# Generate data
times <- 4e5
cols <- 150
data <- as.data.frame(x = matrix(rnorm(times * cols, mean = 5), ncol = cols))
data <- cbind(id = paste0("g", seq_len(times)), data)
pv <- profvis::profvis({
data1 <- data # Store in another variable for this run
# Get column means
means <- apply(data1[, names(data1) != "id"], 2, mean)
# Subtract mean from each column
for (i in seq_along(means)) {
data1[, names(data1) != "id"][, i] <- data1[, names(data1) != "id"][, i] - means[i]
}
})
htmlwidgets::saveWidget(pv, "profvis-slow-code.html")
# In interactive mode, we can directly view the profiling results
if (interactive())
print(pv)Profiling
Code profiling is a fundamental tool for programmers. With profiling, it is possible to identify potential bottle necks in your code, as well as exessive memory usage. Some important things to consider when profiling your code:
It has a stochastic component: Unrelated to computational complexity, a program can exhibit different performance characteristics across different runs. This means that you should always profile your code multiple times and take the average performance as the final result.
It is worthless if the program is too quick: Most of the time, code profiling must be done on programs that take a noticeable amount of time to run. If a program runs too quickly, the overhead of the profiling itself can skew the results. If you still need to address this, you can, for example, do multiple runs or use a larger dataset to increase the run time of the program.
Don’t do it too early: Most of the time, developers tend to optimizing (and thus profiling) their code too early. You don’t want to spend time doing code profiling on something that could quickly change. So it is better to do it on a working code rather than pieces of it.
Instead of profiling the code too early, make sure that you have a good design and implementation plan.
Be strategic: Not everything needs to be optimized. Focus on the parts of the code that are critical for performance and user experience. You can think of it in terms of how much time the program/user spends on each bit.
AI can give you good tips: In my personal experience, AI can be useful doing code profiling too. This works better if you are using an agentic AI, as it is more likely to get good feedback from it (it will test the code for you).
Here is a proposed workflow for profiling and optimizing your code in general
A proposed workflow
Here is a formula to follow when doing code profiling/optimization:
- Ask yourself these questions before you jump into profiling:
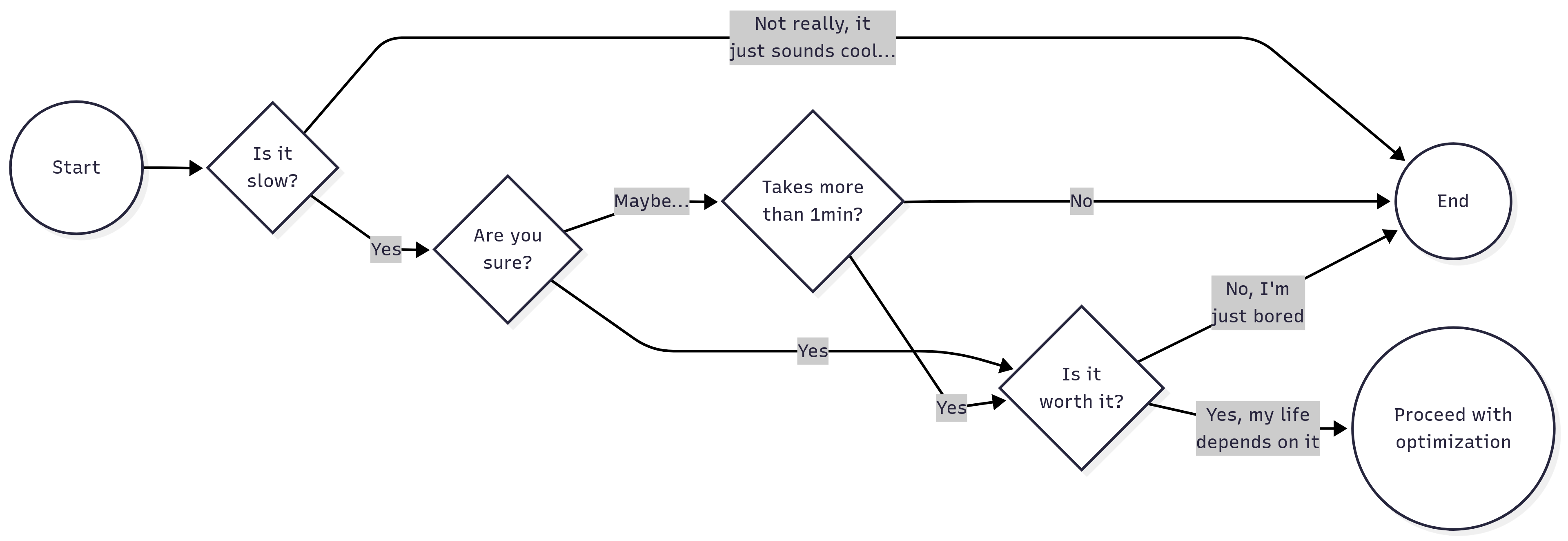
If you succeed, then ensure that the profiling is done in a finite time, this is, use a subset of the data to avoid having long waits. Running the profiler will add overhead computing time, so try to keep it short (e.g., 1 minute).
There may be many things that could be optimized, focus on what would deliver the highest impact. Could be a function that is only called once but takes a long time to execute, or a function that is called multiple times but is relatively fast.
Before making any changes, ensure that you have a backup of your original code, as well as a copy of the current profiling results. You should also ensure to save (if possible) the outcome of the code.
Re-run the profiler and compare performance. If no changes are observed, then go back to step 2. Ensure the new version of the code maintains the same functionality as the original (check the results).
Profiling code in R
In the R programming language, the most used profiling tool comes with the profvis package. The package provides a wrapper of the Rprof function, which is a built-in R function for profiling code. The profvis package makes it easier to visualize the profiling results in a web-based interface.
To use profvis, you first need to install it from CRAN:
install.packages("profvis")Then, you can use it to profile your R code like this:
library(profvis)
profvis({
# Your R code here
})This will execute the code and generate a visualization of the profiling results in a new browser window. You can also save the output using the htmlwidgets package:
pv <- profvis({
# Your R code here
})
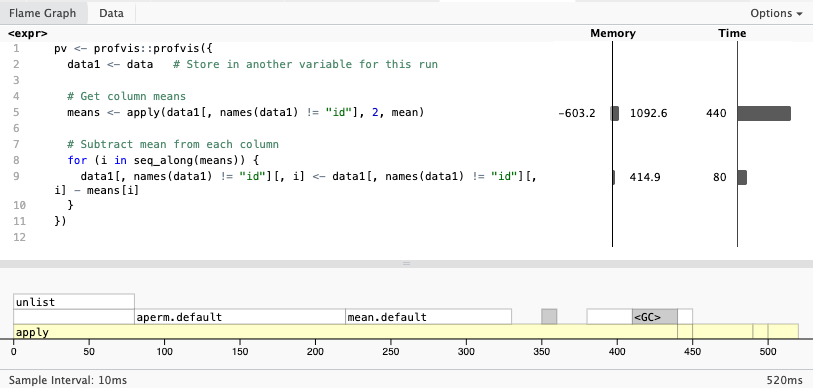
htmlwidgets::saveWidget(pv, "profvis.html")Once open, you will see two visualizations: the flamegraph and the data. The flamegraph is one of the most useful visualizations. It directly maps the time and memory used by each line of code
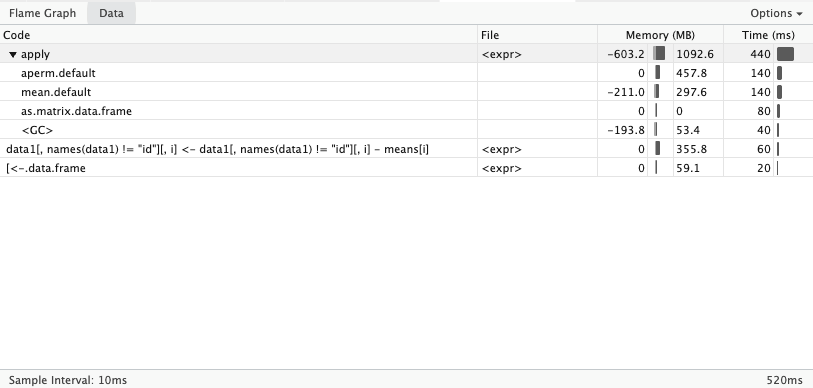
The data visualization shows the distribution of time spent in each function. Using a tree structure, which allows taking deep dives into the call stack.
Tip
When developing R packages, it is a good idea to pair your profvis::profvis call with devtools::load_all() to ensure that all source code is available to the profiler. Otherwise, the flamegraph won’t show your code (it will say “unavailable”).
Exercise: Identifying the bottle neck1
Can you identify where is the bottleneck in the code? What would you do to speed it up?